【tkinter】ラベルにマウスオーバーでツールチップを表示する
tkinterを使って、テキストにマウスオーバーで表示されるツールチップを作成します。
下記画像のようなイメージです。
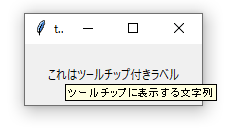
環境
コード
import tkinter as tk class ToolTip: def __init__(self, widget: tk.Label, text: str): self.widget = widget self.text = text self.tip_window = None # マウスオーバーメソッドをバインド self.widget.bind("<Enter>", self.show_tip) # マウスリーブメソッドをバインド self.widget.bind("<Leave>", self.hide_tip) def show_tip(self, event=None): """ツールチップ表示""" # ツールチップが既に存在する or 表示文字列が設定されていない場合、表示処理をしない if self.tip_window or not self.text: return # ツールチップを表示する位置を取得 x = self.widget.winfo_rootx() + 20 y = self.widget.winfo_rooty() + 20 # ツールチップウィンドウを作成 self.tip_window = tk.Toplevel(self.widget) # ツールチップウィンドウの枠を削除 self.tip_window.wm_overrideredirect(True) # ツールチップウィンドウの表示位置を設定 self.tip_window.wm_geometry(f"+{x}+{y}") label = tk.Label( self.tip_window, text=self.text, justify="left", background="#ffffe0", relief="solid", borderwidth=1, font=("tahoma", "8", "normal"), ) label.pack(ipadx=1) def hide_tip(self, event=None): """ツールチップ非表示""" if self.tip_window: self.tip_window.destroy() self.tip_window = None root = tk.Tk() label = tk.Label(root, text="これはツールチップ付きラベル") label.pack(padx=20, pady=20) # テキストをツールチップに表示 ToolTip(label, "ツールチップに表示する文字列") root.mainloop()
説明
ツールチップ用のウィジェットもあるらしいですが、今回はToplevelウィジェットを使用して作ります。
クラスの初期設定
クラス「ToolTip」を作成します。
コンストラクタの引数でwidgetとtextを取得して、メンバ変数に設定します。
self.widgetにはクラス「ToolTip」の親ウィジェットとなるラベルオブジェクトが格納されます。
このラベルオブジェクトはメインウィンドウに表示されるラベルを指します。
self.textにはツールチップに表示する文字列が格納されます。
self.widget.bind("<Enter>", self.show_tip)で、メインウィンドウのラベルに対してマウスオーバー処理を設定します。
<Enter>はtkinterのイベントアクションで、マウスオーバーした際にself.show_tipが処理されるようになります。
self.widget.bind("<Leave>", self.hide_tip)で、マウスポインターがメインウィンドウのラベルから離れた際の処理を設定します。
<Leave>もイベントアクションで、マウスポインターがラベルから離れた際にself.hide_tipが処理されます。
class ToolTip: def __init__(self, widget: tk.Label, text: str): self.widget = widget self.text = text self.tip_window = None # マウスオーバーメソッドをバインド self.widget.bind("<Enter>", self.show_tip) # マウスリーブメソッドをバインド self.widget.bind("<Leave>", self.hide_tip)
ツールチップ表示関数
関数「show_tip」でマウスオーバーした際の処理を設定します。
if self.tip_window or not self.text: return では、ツールチップオブジェクトがすでに存在する、またはツールチップの文字列が設定されていない場合、ツールチップを作成しないようにしています。
x = self.widget.winfo_rootx() + 20、y = self.widget.winfo_rooty() + 20で、ツールチップを表示する位置を取得します。
winfo_rootx()とwinfo_rooty()はメインウィンドウに対するウィジェットの位置を取得します。
winfo_rootx()がX座標(横方向)、winfo_rooty()がY座標(縦方向)の位置です。
+ 20とすることで、メインウィンドウラベルの右に20ピクセル、下に20ピクセルの位置にツールチップを表示します。
self.tip_window = tk.Toplevel(self.widget)で、ツールチップを作成します。
wm_overrideredirect(True)を設定することで、ウィンドウの枠、タイトルバー、最大最小化ボタン、閉じるボタンを非表示にします。
wm_overrideredirect(True)を設定することでツールチップらしい見た目になります。
wm_geometry(f"+{x}+{y}")でツールチップの表示位置を設定します。
tk.Label(~)で、ツールチップに表示する文字列を設定します。
今回は背景色を黄色にすることで、よりツールチップらしい見た目にしています。
def show_tip(self, event=None): """ツールチップ表示""" # ツールチップが既に存在する or 表示文字列が設定されていない場合、表示処理をしない if self.tip_window or not self.text: return # ツールチップを表示する位置を取得 x = self.widget.winfo_rootx() + 20 y = self.widget.winfo_rooty() + 20 # ツールチップウィンドウを作成 self.tip_window = tk.Toplevel(self.widget) # ツールチップウィンドウの枠を削除 self.tip_window.wm_overrideredirect(True) # ツールチップウィンドウの表示位置を設定 self.tip_window.wm_geometry(f"+{x}+{y}") label = tk.Label( self.tip_window, text=self.text, justify="left", background="#ffffe0", relief="solid", borderwidth=1, font=("tahoma", "8", "normal"), ) label.pack(ipadx=1)
ツールチップ非表示関数
関数「hide_tip」で、メインウィンドウラベルからマウスポインターが離れた際の処理を設定します。
if self.tip_window: self.tip_window.destroy() で、ツールチップオブジェクトを削除します。これでマウスポインターが離れた際にツールチップを非表示できます。
def hide_tip(self, event=None): """ツールチップ非表示""" if self.tip_window: self.tip_window.destroy() self.tip_window = None
処理実行
root = tk.Tk()でtkinterを作成し、label = tk.Label(root, text="これはツールチップ付きラベル")でメインウィンドウにラベルを表示します。
ToolTip(label, "ツールチップに表示する文字列")で、ツールチップインスタンスを作成します。
root = tk.Tk() label = tk.Label(root, text="これはツールチップ付きラベル") label.pack(padx=20, pady=20) # テキストをツールチップに表示 ToolTip(label, "ツールチップに表示する文字列") root.mainloop()
【tkinter】複数のtreeviewそれぞれに異なるヘッダー背景色を設定する
treeviewのヘッダー背景色の設定方法について、下記の記事で説明しました。
kankisenkowasuo.hatenablog.com
しかしこの方法だとtreeview全てに同じstyleが適用されてしまうため、treeview毎に異なる背景色を設定することができません。
この記事ではtreeview毎に背景色を設定する方法を説明します。
環境
コード
まずtreeview全てに同一のstyleが設定されているコードです。
import tkinter as tk from tkinter import ttk root = tk.Tk() # スタイルの作成 style = ttk.Style() # レイアウトの再定義 style.layout( "Treeview.Heading", [ ( "Treeheading.cell", { "sticky": "nswe", "children": [ ( "Treeheading.padding", { "sticky": "nswe", "children": [ ("Treeheading.image", {"side": "right", "sticky": ""}), ("Treeheading.text", {"sticky": "we"}), ], }, ) ], }, ) ], ) # Treeviewのスタイル設定 style.configure( "Treeview.Heading", background="green", # 背景色を緑に設定 foreground="red", # 文字色を赤に設定 font=("Helvetica", 10, "bold"), ) # 1つ目のTreeview作成 tree_1st = ttk.Treeview( root, columns=("Column1", "Column2"), show="headings", ) tree_1st.heading("Column1", text="Column 1") tree_1st.heading("Column2", text="Column 2") # データを挿入 tree_1st.insert("", "end", values=("Data 1", "Data 2")) tree_1st.insert("", "end", values=("Data 3", "Data 4")) # Treeviewを配置 tree_1st.pack(expand=True, fill="both") # 2つ目のTreeview作成 tree_2nd = ttk.Treeview( root, columns=("Column1", "Column2"), show="headings", ) tree_2nd.heading("Column1", text="Column 1") tree_2nd.heading("Column2", text="Column 2") # データを挿入 tree_2nd.insert("", "end", values=("Data 1", "Data 2")) tree_2nd.insert("", "end", values=("Data 3", "Data 4")) # Treeviewを配置 tree_2nd.pack(expand=True, fill="both") root.mainloop()
説明
ttk.Styleのconfigureで設定した背景色がtreeview2つ共に反映されています。

これはstyle.configureの第一引き数に"Treeview.Heading"を設定したことが原因です。
"Treeview.Heading"にstyleを設定するとtreeview全てに反映されてしまいます。
# Treeviewのスタイル設定 style.configure( "Treeview.Heading", background="green", # 背景色を緑に設定 foreground="red", # 文字色を赤に設定 font=("Helvetica", 10, "bold"), )
treeviewにstyleを個別に設定するには、style.configureの第一引数をtreeview毎に独自に設定する必要があります。
下記コードではtreeviewに個別に背景色を設定しています。
コード
import tkinter as tk from tkinter import ttk root = tk.Tk() # スタイルの作成 style = ttk.Style() # レイアウトの再定義 style.layout( "Treeview.Heading", [ ( "Treeheading.cell", { "sticky": "nswe", "children": [ ( "Treeheading.padding", { "sticky": "nswe", "children": [ ("Treeheading.image", {"side": "right", "sticky": ""}), ("Treeheading.text", {"sticky": "we"}), ], }, ) ], }, ) ], ) # Treeview 1 用スタイル style.configure( # 修正箇所 "TreeviewFirst.Treeview.Heading", # 1つ目のTreeview用に設定 background="green", foreground="red", font=("Helvetica", 10, "bold"), ) # Treeview 2 用スタイル style.configure( # 修正箇所 "TreeviewSecond.Treeview.Heading", # 2つ目のTreeview用に設定 background="navy", foreground="white", font=("Helvetica", 10, "bold"), ) # Treeview 1 tree_1st = ttk.Treeview( root, columns=("Column1", "Column2"), show="headings", # 修正箇所 style="TreeviewFirst.Treeview", # ここでstyle.configureの第一引き数と合わせる ) tree_1st.heading("Column1", text="Tree 1 - Column 1", anchor="w") tree_1st.heading("Column2", text="Tree 1 - Column 2", anchor="w") tree_1st.insert("", "end", values=("A1", "B1")) tree_1st.insert("", "end", values=("A2", "B2")) tree_1st.pack(fill="both", expand=True, pady=10) # Treeview 2 tree_2nd = ttk.Treeview( root, columns=("Column1", "Column2"), show="headings", # 修正箇所 style="TreeviewSecond.Treeview", # ここでstyle.configureの第一引き数と合わせる ) tree_2nd.heading("Column1", text="Tree 2 - Column 1", anchor="w") tree_2nd.heading("Column2", text="Tree 2 - Column 2", anchor="w") tree_2nd.insert("", "end", values=("X1", "Y1")) tree_2nd.insert("", "end", values=("X2", "Y2")) tree_2nd.pack(fill="both", expand=True, pady=10) root.mainloop()
説明
treeviewそれぞれにstyleを適用させるには、style.configureの第一引き数をtreeview毎に設定します。
# Treeview 1 用スタイル style.configure( # 修正箇所 "TreeviewFirst.Treeview.Heading", # 1つ目のTreeview用に設定 background="green", foreground="red", font=("Helvetica", 10, "bold"), ) # Treeview 2 用スタイル style.configure( # 修正箇所 "TreeviewSecond.Treeview.Heading", # 2つ目のTreeview用に設定 background="navy", foreground="white", font=("Helvetica", 10, "bold"), )
style.configureで設定した第一引数を、Treeviewインスタンス化のタイミングでstyleオプションに設定します。
# Treeview 1 tree_1st = ttk.Treeview( root, columns=("Column1", "Column2"), show="headings", # 修正箇所 style="TreeviewFirst.Treeview", # ここでstyle.configureの第一引き数と合わせる )
# Treeview 2 tree_2nd = ttk.Treeview( root, columns=("Column1", "Column2"), show="headings", # 修正箇所 style="TreeviewSecond.Treeview", # ここでstyle.configureの第一引き数と合わせる )
treeviewそれぞれに背景色が設定できました。

【Tkinter】テキストボックスのサイズを取得し、入力した文字の合計サイズがテキストボックスを超えたら省略する
Tkitnerのテキストボックスに文字を入力し、入力文字がテキストボックスの横幅を超えた場合に省略する方法です。
環境
python : 3.12.3
Tkinter:8.6.13
コード
import tkinter as tk from tkinter import font class EllipsisEntry(tk.Entry): def __init__(self, master=None, **kwargs): self.var = tk.StringVar() super().__init__(master, textvariable=self.var, **kwargs) self.font = font.Font(font=self["font"]) self.bind("<KeyRelease>", self._check_width) def _check_width(self, event=None): full_text = self.var.get() width = self.winfo_width() # エントリーの表示ピクセル幅 print("入力フルテキスト", full_text) print("テキストボックスの横幅(ピクセル)", width) print("入力文字の合計幅", self.font.measure(full_text)) # 全部表示できるか判定 if self.font.measure(full_text) <= width: return # 全部入るなら何もしない # 収まらない場合、「...」を頭につけて短縮 ellipsis = "..." shortened = full_text while self.font.measure(ellipsis + shortened) > width and shortened: shortened = shortened[1:] self.var.set(ellipsis + shortened) root = tk.Tk() entry = EllipsisEntry(root, width=30) entry.pack(padx=10, pady=10) root.mainloop()
説明
tk.Entryを継承したEllipsisEntryクラスを作成します。
__init__のfont.Font(font=self["font"])により、EllipsisEntryのfontの情報を元にfont.Fontのインスタンスを作成します。
このインスタンスはメソッド「__check_width」で入力値のピクセルを計算する際の元情報になります。
self.bind(<KeyRelease>, self._check_width)により、EllipsisEntryクラスにメソッド「_check_width」をbindし、文字を入力する度「_check_width」が呼ばれるようにします。
class EllipsisEntry(tk.Entry): def __init__(self, master=None, **kwargs): self.var = tk.StringVar() super().__init__(master, textvariable=self.var, **kwargs) self.font = font.Font(font=self["font"]) self.bind("<KeyRelease>", self._check_width)
_check_widthでは入力文字と入力文字の合計ピクセル、テキストボックスの横幅ピクセルを取得します。
self.var.get()により入力文字を取得し、font.Fontのメソッド「measure」により入力文字の横幅を取得します。
また、メソッド「winfo_width」によりEllipsisEntryのテキストボックスの横幅を取得します。
if self.font.measure(full_text) <= widthで入力文字がテキストボックスの幅を超えたか判定します。
超えた場合は入力文字の先頭に「...」を結合し、「... + {入力文字}」がテキストボックスの横幅に収まるまで入力文字を先頭から削除します。
def _check_width(self, event=None): full_text = self.var.get() width = self.winfo_width() # エントリーの表示ピクセル幅 print("入力フルテキスト", full_text) print("テキストボックスの横幅(ピクセル)", width) print("入力文字の合計幅", self.font.measure(full_text)) # 全部表示できるか判定 if self.font.measure(full_text) <= width: return # 全部入るなら何もしない # 収まらない場合、「...」を頭につけて短縮 ellipsis = "..." shortened = full_text while self.font.measure(ellipsis + shortened) > width and shortened: shortened = shortened[1:] self.var.set(ellipsis + shortened)
実際に動きを確かめてみます。
まずは入力文字がテキストボックスに収まっている場合です。

def _check_width(self, event=None): full_text = self.var.get() width = self.winfo_width() # エントリーの表示ピクセル幅 print("入力フルテキスト", full_text) print("テキストボックスの横幅(ピクセル)", width) print("入力文字の合計幅", self.font.measure(full_text)) # 出力 # 入力フルテキスト こんにちは # テキストボックスの横幅(ピクセル) 184 # 入力文字の合計幅 46
入力値の合計幅が46ピクセルで、テキストボックスの横幅に収まっているので省略されていません。
次は省略されるパターンです。

def _check_width(self, event=None): full_text = self.var.get() width = self.winfo_width() # エントリーの表示ピクセル幅 print("入力フルテキスト", full_text) print("テキストボックスの横幅(ピクセル)", width) print("入力文字の合計幅", self.font.measure(full_text)) # 出力 # 入力フルテキスト こんにちはこんばんはおはようございます。 # テキストボックスの横幅(ピクセル) 184 # 入力文字の合計幅 186
今度は入力値の合計が186ピクセルでテキストボックスの横幅を超えたため、先頭に「...」が加えられ省略されます。
省略後のピクセル値を取得してみると177ピクセルで、テキストボックスに収まるように省略されています。
def _check_width(self, event=None): full_text = self.var.get() width = self.winfo_width() # エントリーの表示ピクセル幅 print("入力フルテキスト", full_text) print("テキストボックスの横幅(ピクセル)", width) print("入力文字の合計幅", self.font.measure(full_text)) # 出力 # 入力フルテキスト ...にちはこんばんはおはようございます。 # テキストボックスの横幅(ピクセル) 184 # 入力文字の合計幅 177
【python】catch-allアンパックでlistの値を分割して取得する
アスタリスク付きの引数によるcatch-allアンパックを使うことで、指定した変数への代入値以外の全ての値を受け取ることができます。
例えばスライスで分割していた処理をアンパックで置き換えることができます。
環境
python : 3.12.3
コード
fruits = ["リンゴ", "ミカン", "メロン", "バナナ", "パイナップル"] # スライス first = fruits[0] others = fruits[1:] print(first, others) # 出力 # リンゴ ['ミカン', 'メロン', 'バナナ', 'パイナップル'] # catch-allアンパック パターン1 first, *others = fruits print(first, others) # 出力 # リンゴ ['ミカン', 'メロン', 'バナナ', 'パイナップル'] # catch-allアンパック パターン2 first, *others, last = fruits print(first, others, last) # 出力 # リンゴ ['ミカン', 'メロン', 'バナナ'] パイナップル
スライスを利用した分割では、1つ目の値とそれ以降の値をスライスで取得していますが、 可読性が良くないのと、 indexの指定ミスによるlist index out of rangeが発生する可能性があります。
# スライス first = fruits[0] others = fruits[1:] print(first, others) # 出力 # リンゴ ['ミカン', 'メロン', 'バナナ', 'パイナップル']
アスタリスク付きの引数を使用して「*others」と書くとcatch-allアンパックが動作し、firstに代入した値以外が全てothersに代入されます。
下記の例だとfirstに「リンゴ」が代入され、リンゴ以外の値「'ミカン', 'メロン', 'バナナ', 'パイナップル'」がothersにlistの形式で代入されます。
そのため、list index out of rangeが発生する可能性が無くなります。
# catch-allアンパック パターン1 first, *others = fruits print(first, others) # 出力 # リンゴ ['ミカン', 'メロン', 'バナナ', 'パイナップル']
また、catch-allアンパックはどこでも書けるので、*othersの後に変数を置いて最後の値を別に取得することもできます。
下記の例ではfirstに「リンゴ」、lastに「パイナップル」、それ以外の値がothersに代入されます。
# catch-allアンパック パターン2 first, *others, last = fruits print(first, others, last) # 出力 # リンゴ ['ミカン', 'メロン', 'バナナ'] パイナップル
【python】walrus演算子の代入式でコードの重複を防ぐ
pythonの3.8から登場したwalrus演算子で代入式(a := b)を使用し、if文の条件式などに記述することでコードの重複を防ぐことができます。
環境
python : 3.12.3
コード
下記は代入式を使用していないコードです。
animals = {"monkey": 10, "lion": 5}
# 代入文
monkey_num = animals["monkey"]
if monkey_num:
print(f"猿の数は{monkey_num}です。")
else:
print("猿はいません。")
# 出力
# 猿の数は10です。
monkey_numに値を設定していますが、monkey_numを使用しているのはifの条件式とifのネスト内のみで、else内とそれ以降のコードでは使用していません。
変数の使用箇所が限定的な場合、walrus演算子を利用するとコードを簡潔に記述することができます。
下記がwalrus演算子を使用したコードです。
animals = {"monkey": 10, "lion": 5}
# walrus演算子で書き換え
if monkey_num := animals["monkey"]:
print(f"猿の数は{monkey_num}です。")
else:
print("猿はいません。")
# 出力
# 猿の数は10です。
a := bと記述することで条件式内でも変数に値を設定することができます。
そのまま条件式の条件として利用され、ifネスト内での関数にも利用されています。
また、walrus演算子と比較演算子を同時に使用することもできます。
if条件式でwalrus演算子を()でくくることで比較演算子を使用できます。
animals = {"monkey": 10, "lion": 5}
# 代入式と比較演算子
if (monkey_num := animals["monkey"]) >= 0:
print(f"猿の数は{monkey_num}です。")
else:
print("猿はいません。")
# 出力
# 猿の数は10です。
リスト内包表記でwalrus演算子を使用する
リスト内包表記でもwalrus演算子を使用することができます。
以下は、リストの値を2乗した値が10を超えていたら変数に格納する処理を、walrus演算子を使用して記述しています。
walrus演算子で定義した変数「sq」の値を、変数「squares_over_10」に格納しています。
numbers = [1, 2, 3, 4, 5] squares_over_10 = [sq for x in numbers if (sq := x**2) > 10] print(squares_over_10) # 出力: [16, 25]
【python】itertools.zip_longestを使って、長さの異なるイテラブルをイテレーションする
pythonのzip関数を使用すると複数のイテラブルを同時にイテレーションできますが、
イテラブルの長さが異なる場合、長い側は省略されます。
itertools.zip_longestを使用することで、長い側のイテラブルを省略せずに出力できます。
※イテラブル:繰り返し可能なオブジェクト
環境
python : 3.12.3
コード
import itertools names = ["田中", "鈴木", "山田"] counts = [1, 2, 3, 4] print("--------------------------------------------") # zip関数を使用した場合 for name, count in zip(names, counts): print(f"名前:{name} 数:{count}") print("--------------------------------------------") # itertools.zip_longestを使用した場合 for name, count in itertools.zip_longest(names, counts): print(f"名前:{name} 数:{count}") print("--------------------------------------------") # itertools.zip_longestでfillvalueオプションを使用した場合 for name, count in itertools.zip_longest(names, counts, fillvalue="-"): print(f"名前:{name} 数:{count}") print("--------------------------------------------") # 出力 # -------------------------------------------- # 名前:田中 数:1 # 名前:鈴木 数:2 # 名前:山田 数:3 # -------------------------------------------- # 名前:田中 数:1 # 名前:鈴木 数:2 # 名前:山田 数:3 # 名前:None 数:4 # -------------------------------------------- # 名前:田中 数:1 # 名前:鈴木 数:2 # 名前:山田 数:3 # 名前:- 数:4 # --------------------------------------------
説明
zip関数を使用した場合は変数「counts」のサイズが変数「names」より大きいため、値の4が省略されてイテレーションされます。
# zip関数を使用した場合 for name, count in zip(names, counts): print(f"名前:{name} 数:{count}") # 出力 # 名前:田中 数:1 # 名前:鈴木 数:2 # 名前:山田 数:3
itertools.zip_longestを使用した場合は、変数「counts」の4は省略されずに出力され、「names」のサイズが足りない分はNoneで出力されます。
# itertools.zip_longestを使用した場合 for name, count in itertools.zip_longest(names, counts): print(f"名前:{name} 数:{count}") # 出力 # 名前:田中 数:1 # 名前:鈴木 数:2 # 名前:山田 数:3 # 名前:None 数:4
itertools.zip_longestにオプションfillvalueを設定すると、足りなかった分の出力にNoneではなく、fillvalueで設定した値が出力されます。
# itertools.zip_longestでfillvalueオプションを使用した場合 for name, count in itertools.zip_longest(names, counts, fillvalue="-"): print(f"名前:{name} 数:{count}") # 出力 # 名前:田中 数:1 # 名前:鈴木 数:2 # 名前:山田 数:3 # 名前:- 数:4
Tkinterでボタンが押されたままになってしまう現象を回避
Tkinterでボタン押下時の処理を設定した際、ボタンを押すと凹んだままになることがあります。
その回避方法を説明します。
環境
python : 3.12.3
Tkinter:8.6.13
コード
下記のコードを実行します。
import tkinter as tk from tkinter import filedialog def select_file(event): # ファイル選択ダイアログを表示 filename = filedialog.askopenfilename( title="ファイルを選択してください", filetypes=[("テキストファイル", "*.txt"), ("すべてのファイル", "*.*")], ) if filename: print("選択されたファイル:", filename) root = tk.Tk() root.title("ファイル選択ダイアログの例") root.geometry("300x150") btn = tk.Button(root, text="ファイルを選択") btn.bind("<Button-1>", select_file) btn.pack(pady=30) root.mainloop()
下記の画面が表示されます。

ボタンを押してみるとファイル選択ダイアログが表示されますが、ダイアログを閉じた後に画面を見るとボタンが凹んだままになっています。

ボタン押下時の処理をボタンウィジェットのオプション「command」ではなく、bindメソッドで設定した際にたまに起こるようです。
下記がボタンが凹んだままにならないように修正したソースコードです。
import tkinter as tk from tkinter import filedialog def select_file(): # ファイル選択ダイアログを表示 filename = filedialog.askopenfilename( title="ファイルを選択してください", filetypes=[("テキストファイル", "*.txt"), ("すべてのファイル", "*.*")], ) if filename: print("選択されたファイル:", filename) # afterを使って処理を1ミリ秒遅らせる def on_click(event) -> None: root.after(1, select_file) root = tk.Tk() root.title("ファイル選択ダイアログの例") root.geometry("300x150") btn = tk.Button(root, text="ファイルを選択") btn.bind("<Button-1>", on_click) btn.pack(pady=30) root.mainloop()
説明
bindメソッドでselect_fileを直接呼び出すのではなく、on_clickを間に挟み、afterメソッドで1ミリ秒遅らせてselect_fileを呼び出すことでボタンが凹んだままにならないようにしています。
ダイアログを表示してキャンセルしても

ボタンは元に戻っています。
